· Bernard Ko · API · 7 min read
Getting Started with RapidAPI using Python
A quick start guide on how to make requests to RapidAPI using python. We show code examples in their simplest form demonstating use of python urllib, python requests and an asynchronous example using python httpx with asyncio.
In this tutorial, we will demonstrate how to consume APIs on RapidAPI using the various available ways of making http requests in the python programming language.
For this tutorial, we will be using the Parazun Amazon Data API available on RapidAPI. First we will need to get an RapidAPI account ready by subscribing to the free basic plan and getting the API key so that we can make our requests.
Parazun Amazon Data API is a real-time web scraping api which allows any user to get up-to-date data from all of Amazon’s worldwide marketplace websites easily without getting into the nitty gritty of web scraping such as handling captchas and proxies.
To follow this article, we assume you know the some basic syntax of python 3, how to installing python packages using pip and how to start the python interactive console from command line.
Subscribe to Parazun Amazon Data API
If you haven’t already, register for an account at RapidAPI at https://rapidapi.com/auth/sign-up
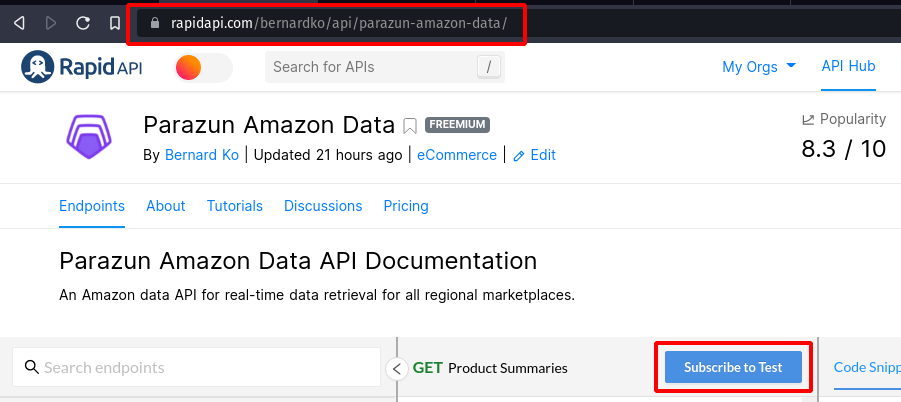
Visit https://rapidapi.com/bernardko/api/parazun-amazon-data/ and click on the “Subscribe to Test” button. 
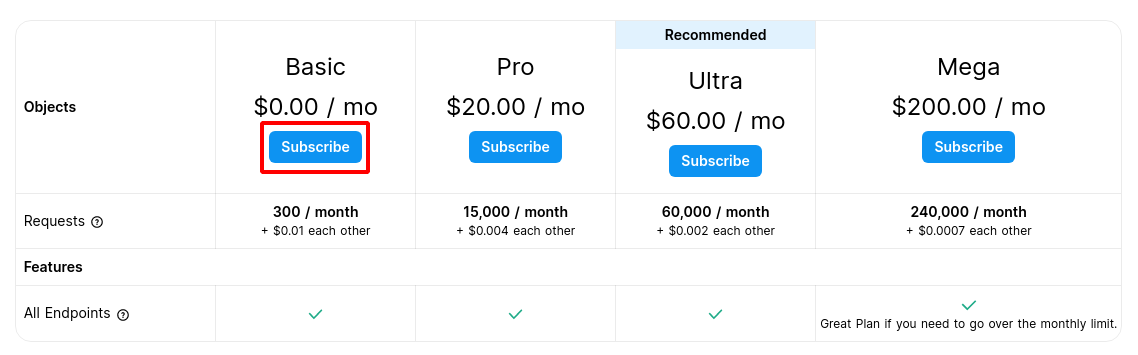
You will be brought to the Pricing page, click on the “Subscribe” button under the Basic Plan. 
Next you will be taken to the subscribe page. RapidAPI requires a credit card to subscribe to APIs. Make sure you see on the right side of the page that the Total Due Today is “$0.00”. Enter your credit card details and click “Pay Now”.
Now we need to gather the information we need to make the API request.
Gather request details and create the URL
Next, we will collect the details we will need to make the request. We will using the product endpoint which will grab all the data on Amazon’s product page and return the data in clean and ready to use JSON format.
Go back to https://rapidapi.com/bernardko/api/parazun-amazon-data/ and on the left side of the page, click on “Product Detail”. 
On the right side of the same page, click on the drop down menu and select “Shell” and then select “cURL”. A script will show up below which will make it easy for you to copy and paste the required header information and URL. Copy the information in the red box below. 
What you should have now:
https://parazun-amazon-data.p.rapidapi.com/product/
x-rapidapi-host : parazun-amazon-data.p.rapidapi.com
x-rapidapi-key : <Your RapidAPI Key>
The “x-rapidapi-key” which is blurred in the screenshot is a secret key and you should keep it in a safe place.
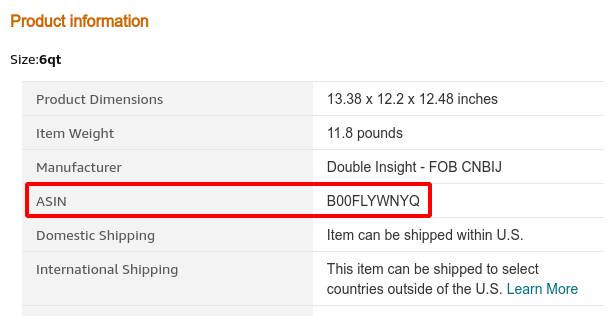
Next we will need a Amazon product ASIN code. ASIN codes are Amazon’s code for uniquely identifying products in their catalog. In this demonstration we will use B00FLYWNYQ which is the ASIN code for an instant pot pressure cooker.
Also, we will need the region code of the Amazon marketplace that these products are listed on, in this case for the US Amazon marketplace, it is US. All Amazon Marketplaces is supported. For a list of other region codes please refer to https://rapidapi.com/bernardko/api/parazun-amazon-data/ documentation.
Lets combine the endpoint URL, product ASIN and region to create the full request URL
https://parazun-amazon-data.p.rapidapi.com/product/?asin=B00FLYWNYQ®ion=US
Notice that the parameter name for the ASIN code is asin and the parameter name for the region code is region.
We now have all the information we need to make the request.
Make requests using urllib
Python urllib is part of the standard library and can be used without installing additional python packages with pip package manager.
In the following snippet of code, we show a simple example of using urllib to make the request. Here are the description of the steps we take to make the request.
- Import the json module and the urlopen function.
- Set the variables
urlto the URL we created above. - Instantiate a request object using the URL and call
add_headerto add RapidAPI authentication headers to the request object. Next, callurlopento start the connection and callreadto get the results of the request. - Using the json module, we convert the json text from the last step into a python dictionary and print out the title of the product to console.
# Step 1
import json
from urllib.request import Request, urlopen
# Step 2
url = "https://parazun-amazon-data.p.rapidapi.com/product/?asin=B00FLYWNYQ®ion=US"
# Step 3
request = Request(url)
request.add_header("x-rapidapi-host", "parazun-amazon-data.p.rapidapi.com")
request.add_header("x-rapidapi-key", "<Your RapidAPI Key>")
response = urlopen(request)
json_text = response.read()
# Step 4
product = json.loads(json_text)
print(product['title'])
Make requests using Python Requests
Python requests is probably the most popular way in the python community to make http requests. It features a very clean and easy to use API.
First we will need to install this package to use it via pip on the command line:
pip install requests
The snippet below does the follow:
- Import the requests module.
- Set the variables
urlandheaderswith the information collected above. - Make the actual request to the API and call the
resp.json()function on the response object to convert the returned results into a python dictionary. Finally print out the title of the product.
# Step 1
import requests
# Step 2
url = "https://parazun-amazon-data.p.rapidapi.com/product/?asin=B00FLYWNYQ®ion=US"
headers = {
"x-rapidapi-host":"parazun-amazon-data.p.rapidapi.com",
"x-rapidapi-key":"<Your RapidAPI Key>"
}
# Step 3
resp = requests.get(url, headers=headers)
product = resp.json()
print(product['title'])
Make requests using Python HTTPX and AsyncIO
Using python httpx and asyncio, we will demonstrate below how you can efficiently request multiple products from the API simultanously. Httpx is a relatively new module which includes all the features of the python requests module we mention above with the functionality to make requests in a non-blocking, asynchronous manner for enhanced efficiency and performance. We at Parazun use httpx extensively in our web scraping API to concurrently scrape multiple pages simultaneously.
This example is slightly more advanced and will be using the async and await declarations to tell python to run functions asynchronously. This demonstrates how you can make simultaneous non-blocking requests to an API in python.
First install the httpx python package on command line via pip:
pip install httpx
The explanation of the code snippet below is as follows:
- Import the
asyncioandhttpxmodules. - Declare 3 urls for making requests to the API using different product ASINs and set the headers to make the requests from the API keys we collected above.
- Declare a function which asynchronously requests a url using the client, url and headers passed in as parameters. We set a higher timeout here to allow the api request to complete before the default httpx timeout expires.
- Declare an asynchronous function which creates an httpx asynchronous request client and using the client we use execute the get_product function to create task coroutines and add them to a list which are run later. The task list is passed into
asyncio.gatherto asynchronously run all the tasks. - Finally, the main function is passed into the
asyncio.runwhich will run the main function in an event loop.
# Step 1
import asyncio
import httpx
# Step 2
url1 = "https://parazun-amazon-data.p.rapidapi.com/product/?asin=B00FLYWNYQ®ion=US"
url2 = "https://parazun-amazon-data.p.rapidapi.com/product/?asin=B075CYMYK6®ion=US"
url3 = "https://parazun-amazon-data.p.rapidapi.com/product/?asin=B07S85TPLG®ion=US"
headers = {
"x-rapidapi-host":"parazun-amazon-data.p.rapidapi.com",
"x-rapidapi-key":"<Your RapidAPI Key>"
}
# Step 3
async def get_product(client, url, headers):
resp = await client.get(url, headers=headers, timeout=20.0)
product = resp.json()
return product
# Step 4
async def main():
tasks = []
async with httpx.AsyncClient() as client:
tasks.append(get_product(client, url1, headers))
tasks.append(get_product(client, url2, headers))
tasks.append(get_product(client, url3, headers))
products = await asyncio.gather(*tasks)
for product in products:
print(product['title'])
# Step 5
asyncio.run(main())
Conclusion
In the above, we show you 3 ways to make requests to the Parazun Amazon Data API on RapidAPI using python. Hopefully this has been helpful as a guide to start to using RapidAPI. Make sure you try out all the examples in the python interactive console.